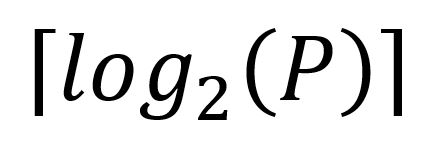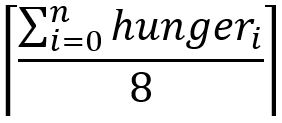Este fue, probablemente, el problema que más tiempo me llevó resolver y que más fundamento teórico/matemático exigía junto al Challenge 3.
Planteamiento
El cuarto desafío consistía en encontrar, dado una serie de lados (longitudes), los tres que formaran el triángulo con el menor perímetro posible. Una vez encontrados dichos lados, si existieran, la salida del problema es dicho perímetro minimizado.
De nuevo, el formato del fichero de entrada tenía una estructura particular:
2 6 13 9 1 13 17 6 7 110 40 10 1 20 60 3
- 1ª fila: número de casos a resolver (2 en el ejemplo)
- Para cada caso:
- 1er carácter: número de lados L a analizar (6 y 7 para los dos casos del ejemplo)
- Siguientes L caracteres: longitud de los lados (13, 9, 1, 13, 17 y 6 en el primer caso)
Para cada caso había que dar una salida indicando el número de caso y el valor del perímetro mínimo calculado siguiendo el formato siguiente:
Case #1: 27 Case #2: IMPOSSIBLE
Entre los lados del primer caso (13, 9, 1, 13, 17, 6) el triángulo de menor perímetro lo forman los lados 13, 1 y 13, dando un perímetro de 13 + 1 + 13 = 27.
Entre los lados del segundo caso (110, 40, 10, 1, 20, 60, 3) no es posible formar ningún triángulo (explicado más adelante).
Solución
Lo primero que hay que considerar es la posibilidad de formar un triángulo con los lados proporcionados. Del ejemplo se deduce que hay una posibilidad de no poder formar un triángulo con ninguna combinación de 3 lados de entre los L proporcionados. Esto viene explicado por el Teorema de la Desigualdad Triangular:
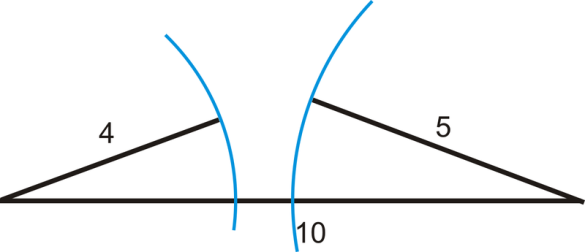
La suma de las longitudes de dos lados de un triángulo es mayor que la longitud del lado restante.
Sin entrar en detalle, esta simple inecuación basta para resolver, en principio, el problema planteado.
La codificación de este problema pasaba por analizar, para cada conjunto de lados posibles, todas las combinaciones de lados mediante la función combinations del módulo itertools.
for case in range(cases):
sides = [int(i) for i in infile.readline().split()]
min_perimeter = 0
del sides[0]
sides.sort()
for a, b, c in itertools.combinations(sides, 3):
if a + b > c and b + c > a and a + c > b:
min_perimeter = a + b + c
break
if min_perimeter == 0:
outfile.write(
"Case #" + str(case + 1) + ": " + "IMPOSSIBLE" + "\n")
else:
outfile.write("Case #" + str(case + 1) + ": " + str(
min_perimeter) + "\n")
Si los lados a, b y c cumplían con la desigualdad triangular, al estar la lista de lados ordenada, bastaba para identificar su perímetro como el mínimo posible. En caso de no haber identificado un nuevo perímetro distinto de 0, la inecuación no se cumpliría nunca y ese caso se declararía IMPOSSIBLE. Es necesario recalcar la importancia de tener la lista ordenada, ya que dado el tamaño de los ficheros de entrega (1000 lados a analizar para 131 casos), se hace imposible analizar todas las combinaciones en un tiempo razonable.
Puedes consultar la implementación completa en Python de este desafío en GitHub y el resumen de mis impresiones de esta edición en esta entrada del blog.